[1] "pescetarisch" "pescetarisch" "omnivore" "omnivore" "vegetarisch"
[6] "omnivore" "vegetarisch" "omnivore" "vegan" "vegan"
[11] "vegetarisch" "vegetarisch" "vegan" "vegan" "vegan"
[16] "vegetarisch" "vegetarisch" "omnivore" "omnivore" "omnivore"
[21] "omnivore" "pescetarisch" "pescetarisch" "vegan" "vegetarisch"
[26] "vegan" "vegan" "pescetarisch" "vegan" "pescetarisch"
[31] "omnivore" "pescetarisch" "omnivore" "vegan" "omnivore"
[36] "omnivore" "omnivore" "omnivore" "omnivore" "vegetarisch"
[41] "vegetarisch" "vegetarisch" "omnivore" "pescetarisch" "pescetarisch"
[46] "pescetarisch" "omnivore" "omnivore" "pescetarisch" "vegetarisch" 4 Deskriptive Statistik
In der deskriptiven Statistik zielt man darauf ab, Daten zu erfassen und ihre wesentlichen Merkmale verständlich darzustellen. Dies erfolgt durch die Berechnung verschiedener Kennzahlen und die Erstellung grafischer Darstellungen, die es ermöglichen, komplexe Datensätze auf eine prägnante Weise zu interpretieren. Welche Kennzahlen und Grafiken dabei sinnvoll eingesetzt werden, hängt stark von der Art der Daten ab. Beispielsweise erfordern kategoriale Daten andere Ansätze als kontinuierliche Daten. Während für kategoriale Daten Häufigkeiten und relative Anteile von Interesse sind, sind für kontinuierliche Daten Kennzahlen wie Mittelwert, Median oder Standardabweichung relevant. Entsprechend müssen auch die grafischen Darstellungen, wie beispielsweise Balkendiagramme für kategoriale Daten oder Histogramme und Boxplots für kontinuierliche Daten, passend gewählt werden, um die Eigenschaften der Daten präzise zu vermitteln.
4.1 Häufigkeiten
Angenommen die beobachteten Daten haben \(m\) verschieden Ausprägungen und \(j=1,2,\ldots , m\) ist der dazugehörige Index.
Definition 4.1 (Absolute Häufigkeit) Die absoluten Häufigkeiten \(H_j\) sind defniert, als die Anzahl wie oft die \(j\)-te Ausprägung beobachtet wurde. Der Stichprobenumfang ist dann gegeben durch die Summe aller \(m\) absoluten Häufigkeiten \(H_j\), also definiert durch
\[ n=\sum_{j=1}^m H_j. \]
Beispiel 4.1 (Ernährungsweise) Es wurden \(n=50\) Personen bezüglich ihrer Ernährungsweise befragt, dabei konnten diese aus den folgenden \(m=4\) Kategorien wählen: omnivore, pescetarisch, vegetarisch und vegan. Es wurden folgende Werte beobachtet:
Daraus ergeben sich folgenden absolute Häufigkeiten:
| Ernährungsweise | absolute Häufigkeiten |
|---|---|
| omnivore | 18 |
| pescetarisch | 11 |
| vegan | 10 |
| vegetarisch | 11 |
Bei einem Vergleich von zwei Stichproben mit unterschiedlichen Stichprobenumfang ist es oft nicht einfach, die Unterschiede zwischen den beiden Stichproben anhand der absoluten Häufigkeiten zu erkennen. Ein Vergleich ist um vieles einfacher, wenn man relative Häufigkeiten betrachtet.
Definition 4.2 (Relative Häufigkeit) Die relativen Häufigkeiten sind defniert durch \(h_j=H_j/n\) und es gilt
\[ \sum_{j=1}^m h_j=1. \]
Die Summe aller relativen Häufigkeiten ist somit \(1\). Die relativen Häufigkeiten werden auch gerne in Prozentwerten ausgedrückt.
Beispiel 4.2 (Fortsertzung Ernärungsweisen) Angenommen bei den \(25\) Personen weiß man auch noch das Geschlecht und möchte die Verteilung der Ernährungsweisen zwischen den beiden Geschlechtern vergeleichen. Die absoluten Häufigkeiten sind in der Tabelle 4.1 aufgelistet.
| Ernährungsweise | Geschlecht | absolute Häufigkeiten |
|---|---|---|
| omnivore | männlich | 7 |
| omnivore | weiblich | 11 |
| pescetarisch | männlich | 1 |
| pescetarisch | weiblich | 10 |
| vegan | männlich | 3 |
| vegan | weiblich | 7 |
| vegetarisch | männlich | 1 |
| vegetarisch | weiblich | 10 |
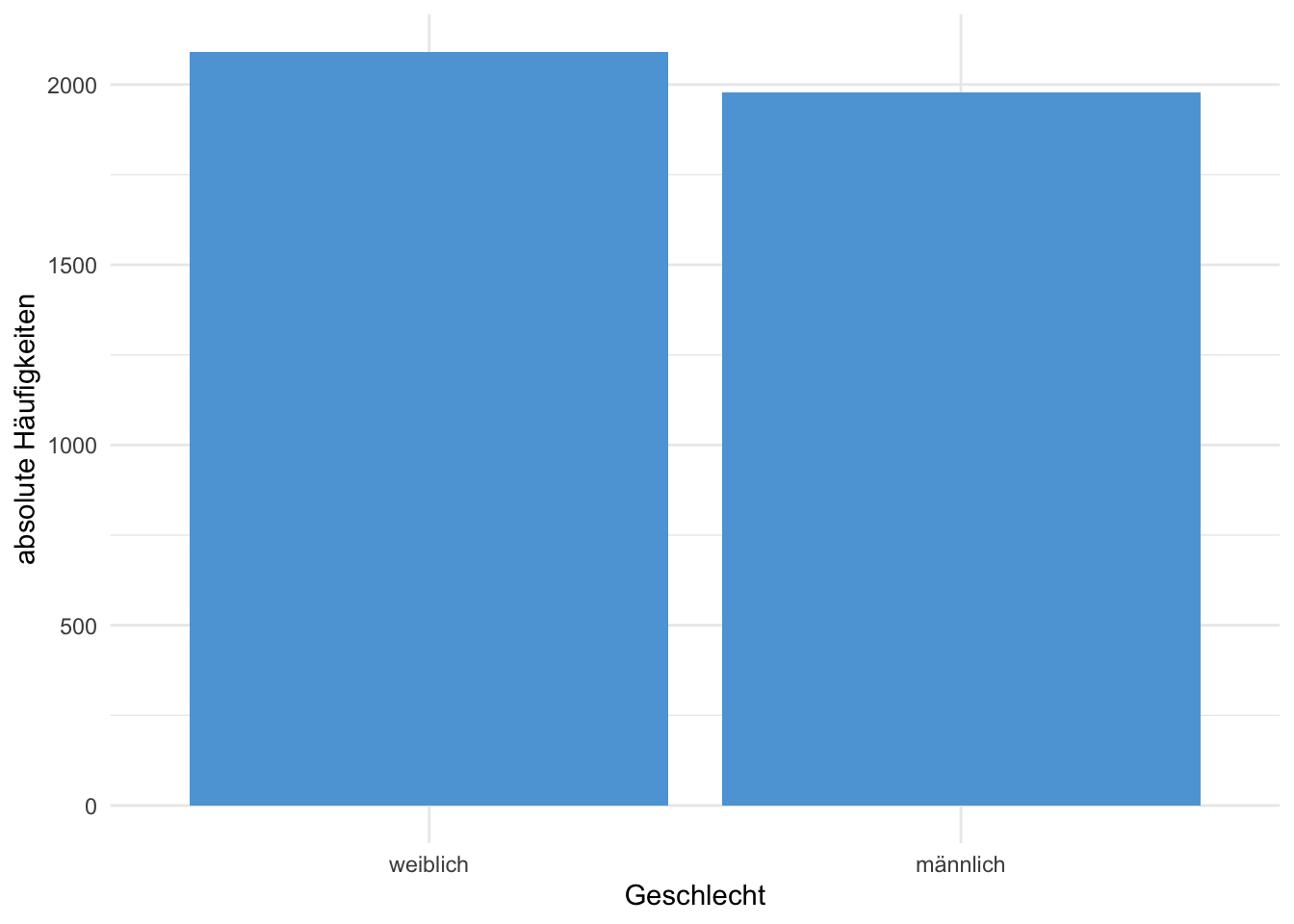
Beispiel 4.3 (Häufigkeiten Geschlecht NHANES Daten) In der Tabelle 4.2 sind die absoluten und relativen Häufigkeiten der weiblichen und männlichen Personen im NHANES Datensatz aufgelistet. In der Abbildung 4.1 sind die absoluten Häufigkeiten als Balkendiagramm dargestellt.
| Geschlecht | absolut | relativ |
|---|---|---|
| weiblich | 2091 | 0.514 |
| männlich | 1978 | 0.486 |
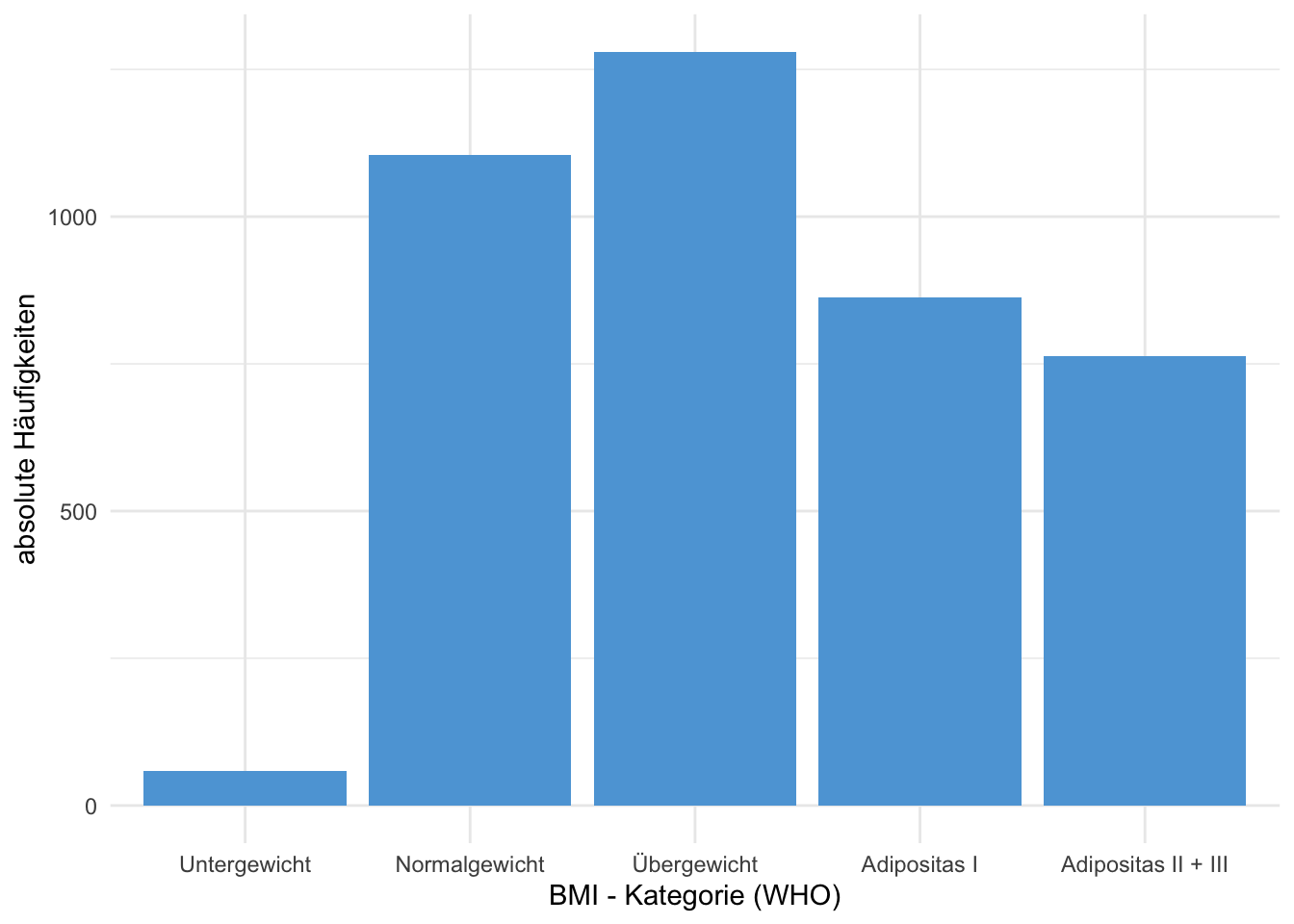
Beispiel 4.4 (Häufigkeiten BMI Kategorien laut WHO in NHANES Daten) In der Tabelle 4.3 sind die absoluten und relativen Häufigkeiten der BMI-Kategorien im NHANES Datensatz aufgelistet. In der Abbildung 4.2 sind die absoluten Häufigkeiten als Balkendiagramm dargestellt.
| BMI-Kategorie | absolut | relativ |
|---|---|---|
| Untergewicht | 59 | 0.014 |
| Normalgewicht | 1104 | 0.271 |
| Übergewicht | 1280 | 0.315 |
| Adipositas I | 863 | 0.212 |
| Adipositas II + III | 763 | 0.188 |
Pivot-Tabelle
- Häufigkeitsverteilung zweier Merkmale
- Geschlecht
- BMI-Kategorie
| weiblich | männlich | |
|---|---|---|
| Untergewicht | 35 | 24 |
| Normalgewicht | 562 | 542 |
| Übergewicht | 581 | 699 |
| Adipositas I | 438 | 425 |
| Adipositas II + III | 475 | 288 |
Relative Häufigkeiten
- bezogen auf das Geschlecht
| weiblich | männlich | |
|---|---|---|
| Untergewicht | 1.7 | 1.2 |
| Normalgewicht | 26.9 | 27.4 |
| Übergewicht | 27.8 | 35.3 |
| Adipositas I | 20.9 | 21.5 |
| Adipositas II + III | 22.7 | 14.6 |
- 27.8 % der Frauen haben einen BMI \(> 25\) und \(\leq 30\)
Relative Häufigkeiten bezogen auf den BMI
| weiblich | männlich | |
|---|---|---|
| Untergewicht | 59.3 | 40.7 |
| Normalgewicht | 50.9 | 49.1 |
| Übergewicht | 45.4 | 54.6 |
| Adipositas I | 50.8 | 49.2 |
| Adipositas II + III | 62.3 | 37.7 |
Bei den Personen in der Gruppe \((25,30]\) sind 54.6% männlich
4.2 Überblick über statistische Kennzahlen
Statistische Kennzahlen lassen sich grob in drei Kategorien unterteilen: Lagekennzahlen, Streuungskennzahlen und Formkennzahlen.
Lagekennzahlen beschreiben die zentrale Tendenz eines Datensatzes, also den typischen oder mittleren Werte, um den sich die Daten gruppieren. Ein Datensatz kann jedoch auch in unterschiedlich große Teile unterteilt werden, um spezifische Werte zu identifizieren, die bestimmte Prozentsätze der Daten repräsentieren. Diese Unterteilungen, wie beispielsweise Quartile, Dezile oder Perzentile, helfen dabei, die Verteilung der Daten genauer zu analysieren und besondere Merkmale innerhalb des Datensatzes hervorzuheben.
Streuungskennzahlen liefern Informationen über die Variabilität oder Streuung der Daten in Bezug auf die zentrale Tendenz. Sie beschreiben, wie stark die einzelnen Datenpunkte um den zentralen Wert, wie den Mittelwert oder Median, variieren. Mit anderen Worten, sie messen, wie weit die Daten im Durchschnitt vom Zentrum abweichen und geben so einen Einblick in die Verteilung und die Homogenität oder Heterogenität des Datensatzes.
Formkennzahlen charakterisieren die Verteilung der Daten, wobei sie insbesondere die Symmetrie der Verteilung und die Steilheit oder Flachheit der Verteilungsgipfel beschreiben. Diese Kennzahlen geben Aufschluss darüber, ob die Daten symmetrisch um die zentrale Tendenz verteilt sind oder ob sie eine Schiefe aufweisen. Darüber hinaus zeigen sie, wie spitz oder flach die Verteilung ist, was auf die Konzentration der Daten um den Mittelwert hinweist.
4.3 Lagekennzahlen
Das arithmetische Mittel oft einfach als Durchschnitt bezeichnet, ist eine der gebräuchlichsten Lagekennzahlen in der Statistik. Es gibt den Durchschnittswert eines Datensatzes an, indem es die Summe aller Werte durch die Anzahl der Werte teilt.
Definition 4.3 (Arithmethisches Mittel) \[ \bar{x}=\frac{x_1 + x_2 + \ldots + x_n}{n}=\frac{1}{n}\sum_{i=1}^n x_i \]
Eigenschaften des arithm. Mittel
Rechenbarkeit: Das arithmetische Mittel kann für jeden Datensatz berechnet werden, der aus quantitativen (numerischen) Daten besteht.
Einfluss von Ausreißern: Das arithmetische Mittel reagiert empfindlich auf Ausreißer, also extrem hohe oder niedrige Werte, da diese die Summe der Daten stark beeinflussen können.
Additivität: Das arithmetische Mittel ist additiv, d.h. das arithmetische Mittel einer Summe von Datensätzen ist gleich der Summe der arithmetischen Mittel der einzelnen Datensätze.
Einheit: Das arithmetische Mittel hat dieselbe Einheit wie die ursprünglichen Daten und ist somit leicht interpretierbar.
Das arithmetische Mittel ist besonders nützlich, wenn die Verteilung der Daten symmetrisch ist und keine Ausreißer vorhanden sind, da es einen zentralen, repräsentativen Wert für den gesamten Datensatz liefert. Das arithmetische Mittel ist bei mehrgipfeligen oder schiefen Verteilungen oft ungeeignet, da es in solchen Fällen den zentralen Wert der Daten nur unzureichend repräsentiert. In einer mehrgipfeligen Verteilung, in der mehrere Häufungsbereiche existieren, kann das arithmetische Mittel zwischen diesen Gipfeln liegen und somit ein verzerrtes Bild der Daten vermitteln. Bei schiefen Verteilungen, wo die Daten asymmetrisch verteilt sind, kann das arithmetische Mittel durch extreme Werte (Ausreißer) stark beeinflusst werden und den Schwerpunkt der Daten falsch darstellen. In solchen Fällen sind alternative Lagekennzahlen wie der Median oder die Moden oft besser geeignet, um die zentrale Tendenz der Daten korrekt abzubilden.
Beispiel 4.5 (Arithmetisches Mittel) Gegeben sei eine Stichprobe der Größe \(n=\) 10 mit folgende Werten:
[1] 5.3 10.2 6.7 8.1 7.6 6.2 8.5 8.3 7.9 11.2Sie Summe dieser Werte ist 80. Dividiert man diese durch den Stichprobenumfang \(n=\) 10 so ergibt sich ein arithm. Mittel \(\bar{x}=\) 8.
Ändert man den letzten Wert von 11.2 zu einem Ausreisser mit einem Wert von 31.2, dann ändert sich die Summe auf 100 und somit auch das arithm. Mittel auf 10. Man erkennt, dass nur ein einziger Wert, der weit weg von den restlichen Werten liegt, das arithm. Mittel stark verändern kann.
4.3.1 Median
Definition 4.4 (Median) Der Median teilt die geordnete Stichprobe in zwei gleich große Hälften. Das bedeutet, dass \(50\)% der Werte kleiner oder gleich dem Median und die anderen \(50\)% der Werte größer oder gleich dem Median sind. Der Median stellt somit den mittleren Wert einer geordneten Stichprobe dar und ist eine robuste Lagekennzahl
Der Median ist besonders nützlich, um die zentrale Tendenz eines Datensatzes zu beschreiben, insbesondere wenn dieser Ausreißer oder eine asymmetrische Verteilung aufweist.
Eigenschaften des Medians:
Robustheit gegenüber Ausreißern: Im Gegensatz zum arithmetischen Mittel wird der Median nicht durch extreme Werte oder Ausreißer beeinflusst. Dadurch ist er ein verlässlicher Indikator für die zentrale Tendenz in Datensätzen mit ungleichmäßiger Verteilung.
Eindeutigkeit: In einer geordneten Stichprobe existiert genau ein Median, sofern die Anzahl der Daten ungerade ist. Bei einer geraden Anzahl von Beobachtungen wird der Median häufig als der Durchschnitt der beiden mittleren Werte definiert.
Anwendbarkeit bei ordinalen Daten: Der Median kann nicht nur für quantitative Daten, sondern auch für ordinale Daten berechnet werden, bei denen die Werte in eine Reihenfolge gebracht werden können, ohne dass exakte Abstände zwischen den Werten bekannt sein müssen.
Lage in der Datenverteilung: Der Median gibt die Position eines zentralen Wertes in der Datenverteilung an, unabhängig von der Form der Verteilung. Er ist besonders nützlich in schiefen Verteilungen, da er die Mitte der Daten besser repräsentiert als das arithmetische Mittel.
Unempfindlichkeit gegenüber der Verteilungsform: Da der Median nur von der Reihenfolge der Daten abhängt und nicht von deren exakten Werten, bleibt er auch bei Veränderungen in der Form der Verteilung (wie Streckung oder Stauchung der Verteilung) stabil.
Der Median ist somit eine wichtige und oft bevorzugte Kennzahl zur Beschreibung der zentralen Tendenz, insbesondere in Fällen, in denen die Daten asymmetrisch verteilt sind oder extreme Werte vorliegen. Der Median ist wie das arithm. Mittel nicht geeignet das Zentrum bei mehr-gipfeligen Verteilungen zu beschreiben.
Beispiel 4.6 (Median) Bei diesem Beispiel werden die gleichen Daten wie beim arithmetischen Mittel verwendet. Für die Berechnung des Median macht es Sinn die Daten zuerst aufsteigen zu sortieren.
[1] 5.3 6.2 6.7 7.6 7.9 8.1 8.3 8.5 10.2 11.2Da der Stichprobenumfang \(n=\) 10 eine gerade Zahl ist, ist der Median der mittlere Wert zwischen den 5 und 6 Wert. Also die Hälfte von der Summe von 7.9 und 8.1. Somit ist der Median 8. Betrachtet man die zweite Stichprobe mit dem Ausreisser:
[1] 5.3 6.2 6.7 7.6 7.9 8.1 8.3 8.5 10.2 31.2so erkennt man bei der sortierten Stichprobe, dass sich hier der 5 und 6 Wert nicht ändert und somit der Median der gleiche ist wie ohne Ausreisser.
Modalwert
Definition 4.13 (Modalwert) Der Modalwert oder Modus ist derjenige Wert einer Stichprobe, der am häufigsten beobachtet wurde. Er stellt die häufigste Ausprägung in den Daten dar und ist insbesondere bei diskreten Werten mit deutlich weniger Ausprägungen als der Stichprobenumfang direkt verwendbar.
4.3.2 Verwendung des Modalwerts:
Direkte Anwendung bei diskreten Daten: Der Modalwert lässt sich besonders gut bei diskreten Daten anwenden, wenn die Anzahl der möglichen Ausprägungen deutlich geringer ist als die Anzahl der Beobachtungen in der Stichprobe. In solchen Fällen ist der Modus einfach der am häufigsten vorkommende Wert.
Anwendung bei stetigen Daten oder Daten mit sehr vielen Ausprägungen:
- Bei stetigen Daten oder solchen mit sehr vielen (theoretisch unendlich vielen) Ausprägungen kann der Modalwert nicht direkt ermittelt werden. In diesen Fällen wird der Beobachtungsraum in Klassen unterteilt.
- Der Modalwert wird dann als der Mittelwert der Klassengrenzen jener Klasse bestimmt, in der die meisten Werte liegen.
- Der ermittelte Modalwert ist abhängig von der Wahl der Klasseneinteilung, was bedeutet, dass die Festlegung der Klassenbreite und -grenzen einen Einfluss auf den Wert des Modus haben kann.
Der Modalwert ist besonders nützlich, um den häufigsten Wert in einem Datensatz zu identifizieren, und spielt eine wichtige Rolle in der deskriptiven Statistik, insbesondere bei der Analyse von Häufigkeitsverteilungen.
4.3.3 Lage
Lagekennzahlen, auch als Ordnungsstatistiken bezeichnet, geben an, wie viel Prozent der Werte in einem Datensatz kleiner als ein bestimmter Wert sind. Dabei wird nicht der Wert selbst vorgegeben, sondern der Prozentwert \(\alpha\) wird fixiert und dann das dazugehörige Wert aus der Stichprobe berechnet. Dieser wird dann als \(\alpha\)-Quantil bezeichnet. Ein bekanntes Beispiel für ein Quantil ist der Median, der das \(50\)%-Quantil darstellt, da \(50\)% der Werte kleiner oder gleich dem Median sind.
Quartile
Die Quartile sind spezielle Quantile, aus dem Namen lässt sich ableiten, das diese Quantile die Daten in 4 (Quarter) Bereiche aufteilt. In jedem Bereich befinden sich \(25\)% der Daten, daher sind die verwendeten Prozentsätze: \(25\)%, \(50\)%, und \(75\)%. Das \(25\)%-Quantil (\(Q_{0.25}\)) wird auch das \(1\).Quartil oder unterer Quartil bezeichnet. Das \(75\)%-Quantil (\(Q_{0.75}\)) wird als \(3\). oder obere Quartil bezeichnet.
Quantile
Definition 4.5 (Quantile) Ein \(\alpha\) Quantil ist jener Wert, bei dem \(n\alpha\) Werte kleiner oder gleich diesem Wert sind.
Spezielle Quantile sind die Quartile und Perzentile. Bei den Perzentilen lässt sich \(\alpha\) in der Regel als \(Z/N\) darstellen, wobei \(Z \in \{1, 2, 3, \ldots, 99\}\) ist und \(N=100\).
4.4 Streuungskennzahlen
4.4.1 Varianz, Standardabweichung
Die Varianz und die Standardabweichung sind grundlegende Streuungsmaße in der Statistik, die Auskunft darüber geben, wie stark die Datenwerte um den Mittelwert eines Datensatzes streuen.
Definition 4.6 (Varianz) Die Varianz ist ein Maß dafür, wie weit die einzelnen Beobachtungen eines Datensatzes durchschnittlich vom arithmetischen Mittel abweichen. Sie wird berechnet, indem man die Abweichungen der einzelnen Werte vom Mittelwert quadriert, diese quadrierten Abweichungen summiert und dann durch die Anzahl der Beobachtungen teilt (für eine Stichprobe wird durch n−1 geteilt, um eine unverzerrte Schätzung zu erhalten).
\[ s^2=\frac{1}{n-1}\sum_{i=1}^n (x_i- \bar{x})^2 \]
Eigenschaften der Varianz:
- Empfindlichkeit gegenüber Ausreißern: Da die Abweichungen quadriert werden, hat die Varianz einen höheren Wert, wenn extreme Werte (Ausreißer) in den Daten vorhanden sind. Dies bedeutet, dass Ausreißer einen großen Einfluss auf die Varianz haben.
- Quadratische Maßeinheit: Die Varianz ist immer positiv, da quadrierte Abweichungen niemals negativ sind. Die Maßeinheit der Varianz ist das Quadrat der ursprünglichen Maßeinheit der Daten, was ihre Interpretation erschweren kann.
- Zentralität: Die Varianz misst die Streuung der Daten um den Mittelwert, wobei größere Werte auf eine größere Streuung hinweisen.
Definition 4.7 (Standardabweichung) Die Standardabweichung ist die Quadratwurzel der Varianz und gibt somit die durchschnittliche Abweichung der Daten vom Mittelwert in den ursprünglichen Maßeinheiten der Daten an.
\[ s=\sqrt{s^2} \]
Eigenschaften der Standardabweichung:
- Maßeinheit: Im Gegensatz zur Varianz hat die Standardabweichung dieselbe Maßeinheit wie die ursprünglichen Daten, was ihre Interpretation intuitiver macht.
- Empfindlichkeit gegenüber Ausreißern: Ähnlich wie die Varianz wird auch die Standardabweichung durch Ausreißer stark beeinflusst, da sie auf den quadrierten Abweichungen basiert.
Zusammen bieten Varianz und Standardabweichung wertvolle Informationen über die Variabilität in einem Datensatz. Während die Varianz mathematisch oft leichter handhabbar ist, bietet die Standardabweichung aufgrund ihrer Maßeinheit eine anschaulichere Interpretation der Streuung der Daten.
4.4.2 Interquartilsrange
Definition 4.8 (Interquartilsrange) Der Interquartilsrange (IQR), auch als Interquartilsabstand bezeichnet, ist ein Streuungsmaß, das die Spannweite der mittleren 50% eines Datensatzes beschreibt. Er wird berechnet als die Differenz zwischen dem dritten Quartil (\(Q_{0.75}\)) und dem ersten Quartil (\(Q_{0.25}\)) eines Datensatzes:
\[ IQR = Q_{0.75} - Q_{0.25} \]
4.4.3 Interquartilsabstand (IQR)
Eigenschaften des Interquartilsabstands:
Robustheit gegenüber Ausreißern: Der IQR ist unempfindlich gegenüber Ausreißern und extremen Werten, da er sich ausschließlich auf die zentralen 50% der Daten konzentriert. Dadurch ist er ein verlässlicheres Streuungsmaß bei asymmetrischen Verteilungen oder bei Vorhandensein von Ausreißern.
Zentralität: Da der IQR nur die Streuung innerhalb der mittleren 50% der Daten misst, liefert er ein konzentriertes Bild der Variabilität um den Median herum, im Gegensatz zu Streuungsmaßen, die die gesamte Datenverteilung berücksichtigen.
Verwendung zur Identifikation von Ausreißern: Der IQR wird häufig verwendet, um Ausreißer zu identifizieren. Werte, die mehr als das 1,5-fache des IQR oberhalb von (Q_3) oder unterhalb von (Q_1) liegen, gelten oft als potenzielle Ausreißer.
Anwendbarkeit bei asymmetrischen Verteilungen: Der IQR ist besonders nützlich, um die Streuung in asymmetrischen Verteilungen zu beschreiben, da er nicht durch extrem hohe oder niedrige Werte beeinflusst wird, wie es bei der Standardabweichung der Fall ist.
Robuster Schätzer für die Standardabweichung: Dividiert man den IQR durch 1.349 so erhält man einen robusten Schätzer für die Standardabweichung
Der Interquartilsabstand ist somit ein wichtiges Maß zur Beschreibung der Streuung in einem Datensatz, das vor allem in Situationen nützlich ist, in denen eine robuste und ausreißerresistente Analyse der Variabilität erforderlich ist.
4.4.4 Mittlere Absolute Abweichung (MAD)
Definition 4.9 (Median Absolute Deviation (MAD)) Die Mittlere Absolute Abweichung (MAD) ist ein Streuungsmaß, das die durchschnittliche Abweichung der Datenwerte von einem zentralen Wert (häufig dem Median) beschreibt. \[ MAD = median | x_i - \tilde{x}| \]
Im Gegensatz zur Varianz oder Standardabweichung berücksichtigt der MAD die absoluten Abweichungen der Datenpunkte vom gewählten zentralen Wert, ohne diese zu quadrieren.
Eigenschaften der Mittleren Absoluten Abweichung:
Robustheit gegenüber Ausreißern: Der MAD ist robust gegenüber Ausreißern, da er auf absoluten Abweichungen basiert und daher weniger von extremen Werten beeinflusst wird als die Varianz oder Standardabweichung. Dies macht ihn besonders geeignet für Datensätze mit ungleichmäßiger Verteilung oder Ausreißern.
Zentralität: Da der MAD üblicherweise vom Median berechnet wird, bietet er ein robustes Maß für die Streuung um die zentrale Tendenz der Daten. Der Median minimiert die Summe der absoluten Abweichungen, was den MAD zu einem natürlichen Streuungsmaß in Verbindung mit dem Median macht.
Einfachere Interpretation: Der MAD ist leichter zu interpretieren als die Varianz, da er in derselben Einheit wie die Daten ausgedrückt wird und nicht die Quadrate der Abweichungen verwendet. Er gibt direkt die durchschnittliche Abweichung der Daten vom Median an.
Nicht so empfindlich wie die Standardabweichung: Da der MAD auf absoluten Abweichungen basiert, reagiert er weniger stark auf Änderungen in den Daten als die Standardabweichung. Das bedeutet, dass der MAD in manchen Anwendungen stabiler und robuster sein kann.
Anwendbarkeit bei allen Datentypen: Der MAD kann sowohl für symmetrische als auch für asymmetrische Verteilungen verwendet werden und ist für verschiedene Datentypen geeignet, einschließlich ordinaler Daten, da er keine Annahmen über die Verteilung der Daten trifft.
Robuster Schätzer für Standardabweichung: Multipliziert man den MAD mit 1.4826 so erhält man einen robusten Schätzer für die Standardabweichung
Insgesamt ist die Mittlere Absolute Abweichung ein nützliches Streuungsmaß in der Statistik, insbesondere wenn eine robuste und leicht interpretierbare Kennzahl für die Streuung der Daten um einen zentralen Wert benötigt wird.
4.4.5 Spannweite
Definition 4.10 (Spannweite) \[ R = \max(x_i) - \min(x_i) \]
- Stark beeinflusst durch Ausreißer
- nicht geeignet um Stichproben unterschiedlicher Größen zu vergleichen
4.5 Formkennzahlen
4.5.1 Schiefe
Definition 4.11 (Schiefe) \[ s_k = \frac {\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^{3}} {\sqrt{ (\frac{1}{n}\sum_{i=1}^n (x_i - \bar{x})^{2})^{3}}} \]
- \(s_k \approx 0\) … symmetrische Verteilung
- \(s_k > 0\) … rechtsschiefe Verteilung
- \(s_k < 0\) … linksschiefe Verteilung
4.5.2 Kurtosis
Definition 4.12 (Kurtosis) \[ kur= \frac{ \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^{4}}{( \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x}^{2})^{2}} -3 \]
- \(kur \approx 0\) … normale Wölbung (wie Normalverteilung)
- \(kur > 0\) … starke Wölbung (steilgipfelig)
- \(kur < 0\) … schwache Wölbung (flachgipfelig)
4.5.3 Histogramm
Für das Histogramm teilt man den Wertebereich der Daten in Klassen ein, und betrachtet die Anzahl der Werte die in die jeweilige Klasse fallen. Für jede Klasse wird nun eine Balken gezeichnet, der so hoch ist, dass die Fläche des Balken die Anzahl der Werte widerspiegelt. Da die Berechnung der Fläche etwas umständlich ist, nimmt man in der Regel gleich große Klassen und trägt pro Klasse als Höhe die Anzahl der Werte pro Klasse auf. Da bei der Klasseneinteilung die Klassen direkt aneinander liegen, gibt es im Gegensatz zum Balkendiagramm keinen Abstand zwischen den Balken.
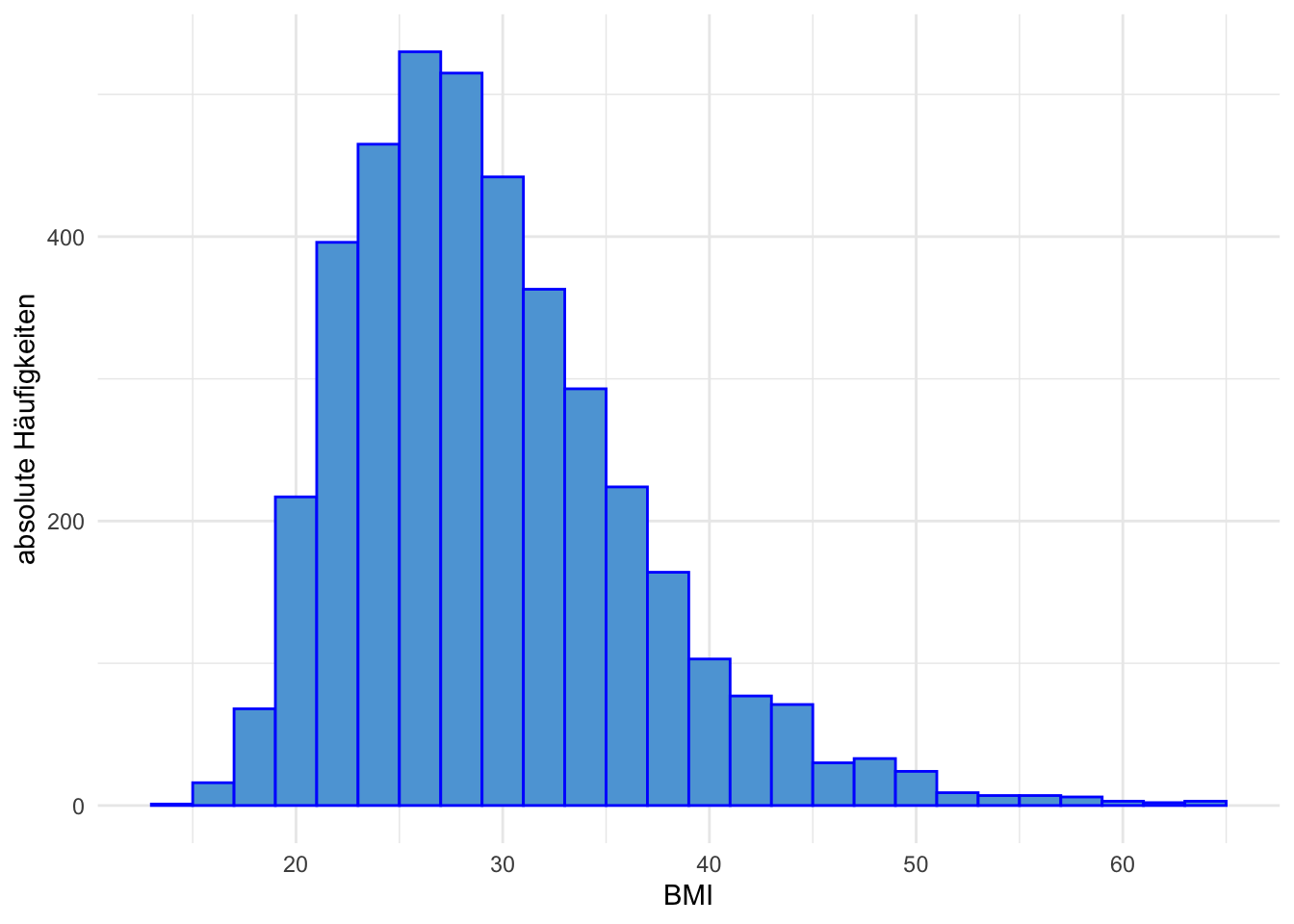
Anzahl der Klassen
Es stellt sich die Frage, wie viele Klassen sollen gemacht werden, beziehungsweise wie groß soll die Klassenbreite sein. Dafür gibt es keine exakte Vorschrift aber eine Faustregel. Diese Fasutregel besagt, dass die Anzahl der Klassen circa \(\sqrt{n}\) betragen soll. Allgemein gilt, dass es nicht weniger als 5 Klassen sein sollen und nicht mehr als 20. Bei einer sehr großen Stichprobe (\(n > 1000\)) kann die Klassenanzahl auch größer als 20 sein. Die Wahl der Klassenbreite kann das Erscheinungsbild des Histogramms stark beeinflussen, daher ist es sinnvoll immer verschiedene Klassenbreiten/anzahl auszuprobieren und jene zu wählen, bei der die Form der Verteilung gut ersichtlich ist.
4.6 Boxplot
4.7 Übungen
Kennzahlen
Übung 4.1 Welche Eigenschaften hat das arithm. Mittel?
Übung 4.2 Welche Eigenschaften hat der Median?
Übung 4.3 Wann ist es besser den Median anstatt das arithm. Mittel zu verwenden, um das Zentrum eine Verteilung zu beschreiben?
Übung 4.4 Bei einer Stichprobe von \(n=80\) Personen wurde der BMI gemessen. Das \(Q_{0.25} = 20\), was sagt es aus?
Übung 4.5 Welche Kennzahlen beschreiben die Variabilität der Daten?
Übung 4.6 Mit welchen Kennzahlen kann man die Form einer Verteilung beschreiben?
Visualisierung
Übung 4.7 Wann verwende ich ein Balkendiagramm und wann ein Histogramm? Worin unterscheiden sich diese beiden Grafiktypen?
Übung 4.8 Welche Aspekte gibt es bei der Erstellung eines Histogramms zu beachten?
Übung 4.9 Auf welchen Kennzahlen basiert die Darstellung des Boxplots?
Übung 4.10 Was erkenne ich im Histogramm, aber nicht im Boxplot?
Übung 4.11 Was erkenne ich im Boxplot, aber nicht im Histogramm?
Übung 4.12 Es wurde bei 100 Kraft-Sportler:innen und bei 100 Fitness-Sportler:innen der mittlere Proteingehalt (in %) der Nahrung von einer Woche gemessen. Die Daten sind in den beiden Grafiken A und B dargestellt. Beschreiben Sie alle Aspekte, die Sie aus den beiden Grafiken ablesen und interpretieren Sie diese.
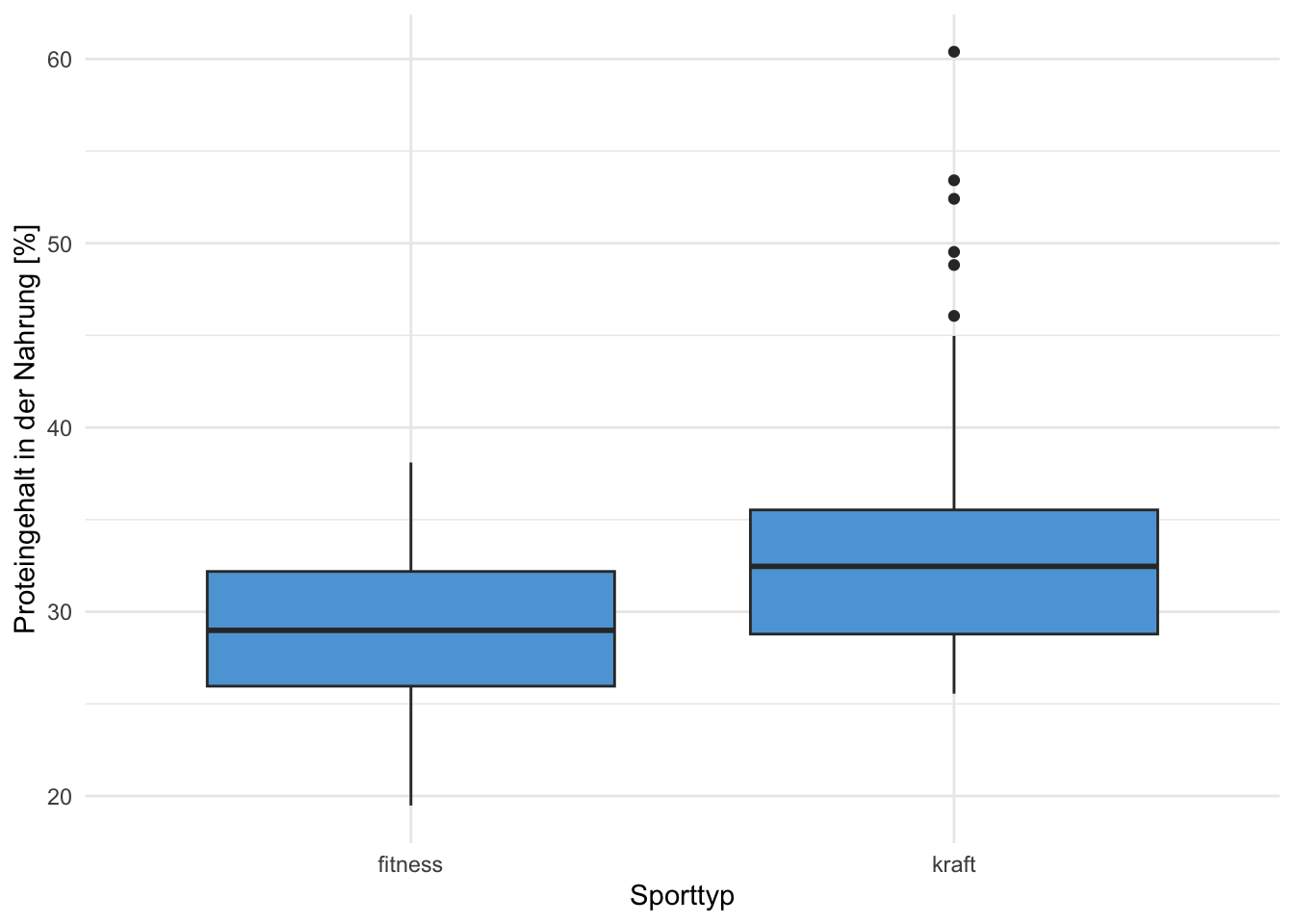
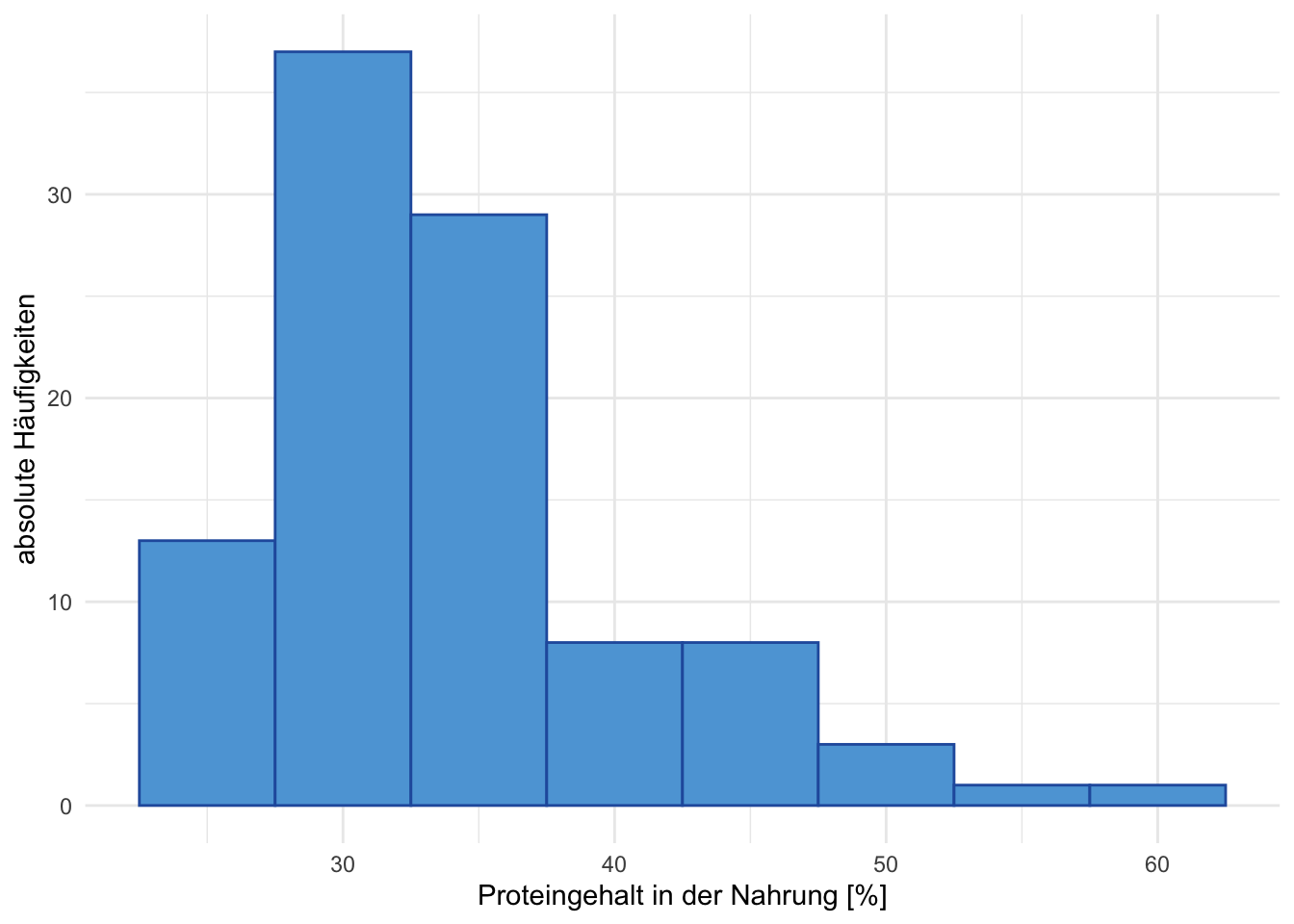
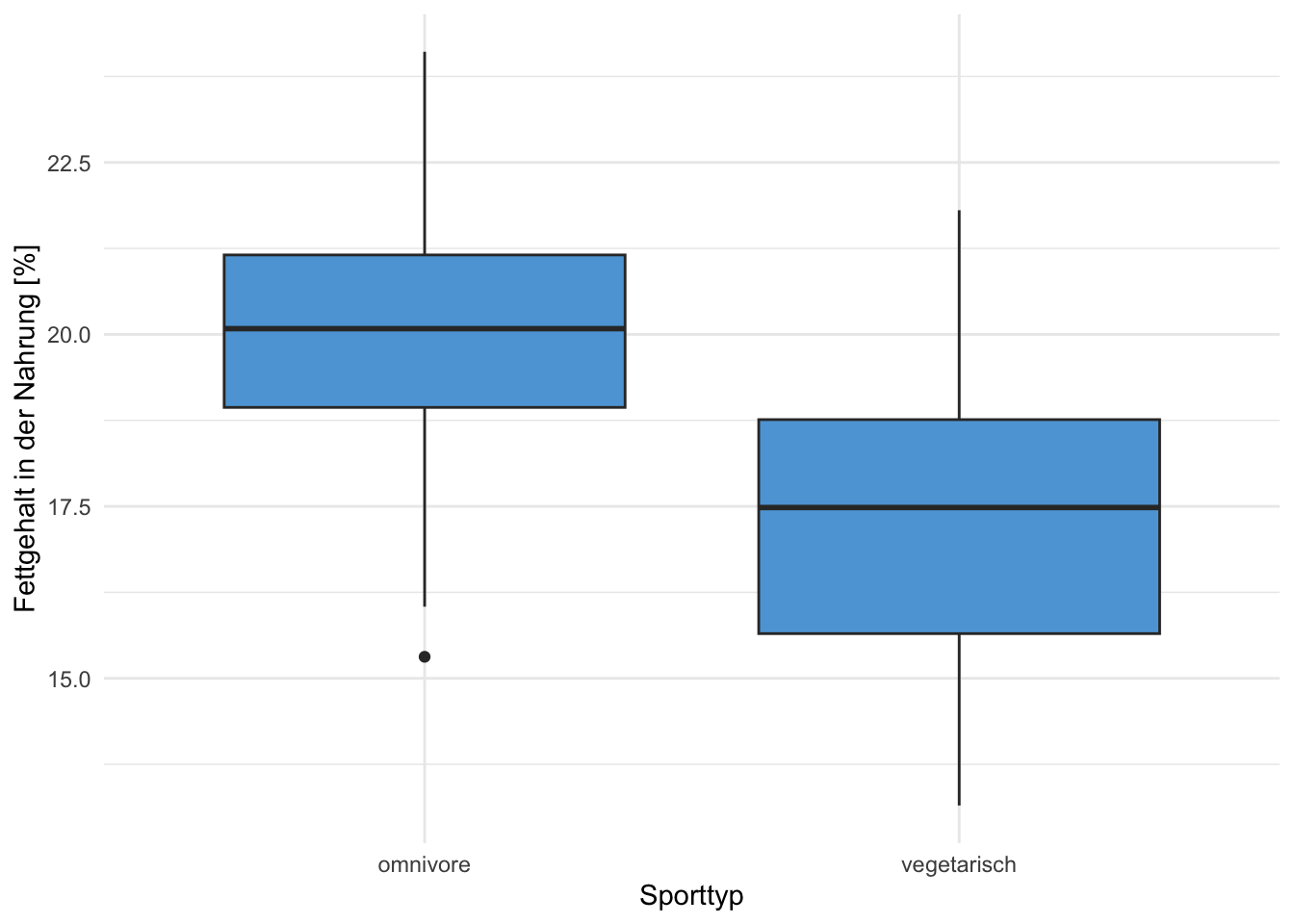
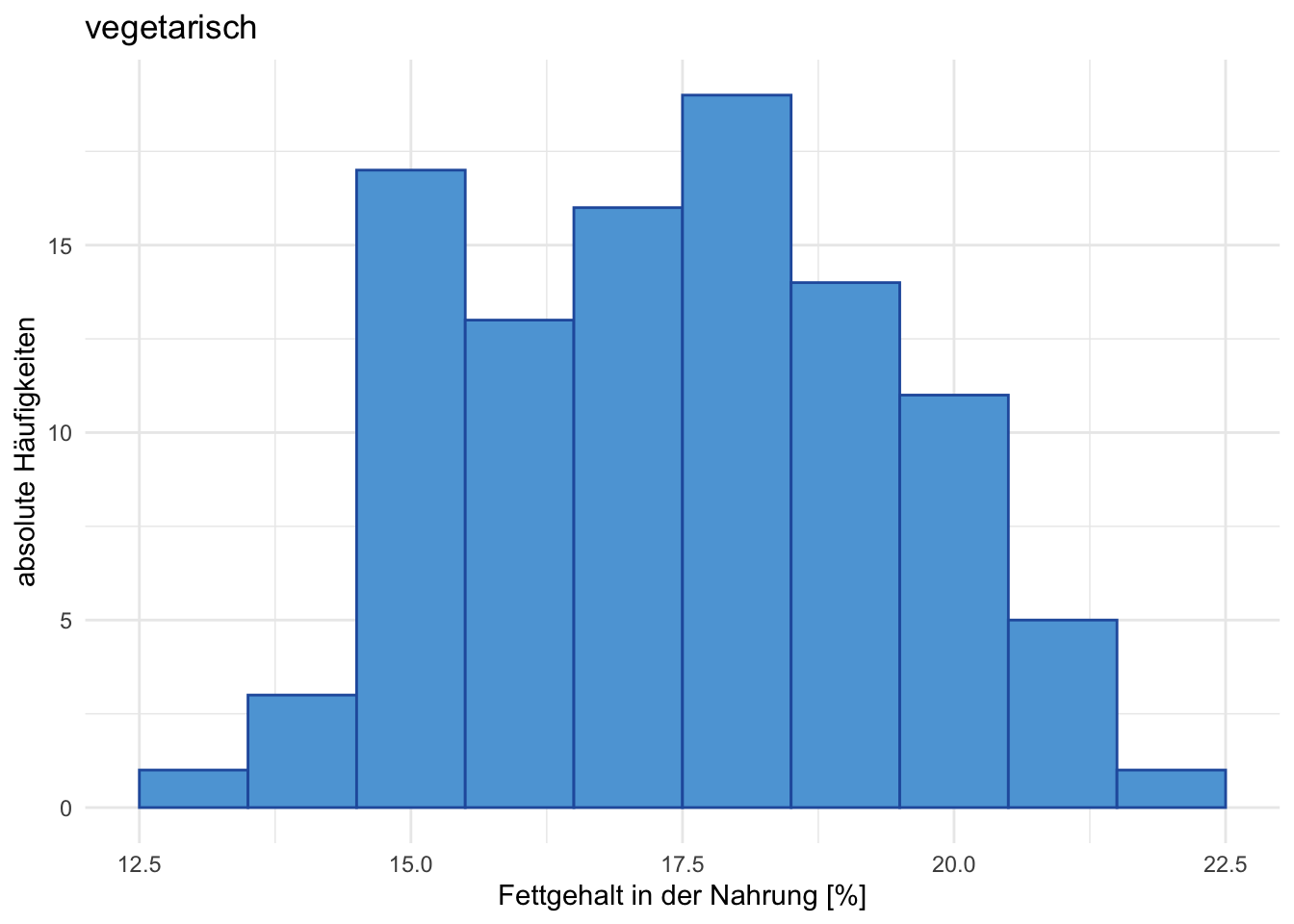
Übung 4.13 Es wurde bei 100 Omnivore und bei 100 Vegetarier der mittlere Fettgehalt (in %) der Nahrung von einer Woche gemessen. Die Daten sind in den beiden Grafiken A und B dargestellt. Beschreiben Sie alle Aspekte, die Sie aus den beiden Grafiken ablesen und interpretieren Sie diese.